How does Python Execution work¶
To fully understand specific Python security threats and vulnerabilities, it is essential to have a solid understanding of how Python runs. This section covers bytecode compilation, the PVM (Python Virtual Machine), and how Python handles memory and dynamic typing.
To understand which security threats are relevant to Python code, knowledge of the internal workings of the Python interpreter is required.
The default and most widely used interpreter is CPython, distributed by the Python Software Foundation (PSF). The core CPython source code cannot be easily compromised; multiple defensive measures are taken to prevent weaknesses in the code and to protect against supply chain attacks. While trust is essential, verification is better: the open-source nature of Python allows anyone to inspect the code or validate the PSF’s processes if required.
Most secure Unix distributions and all BSD systems require that CPython is built from source. Some distributions use reproducible builds to minimise the risk of supply chain attacks on the CPython code.
While Python is an interpreted language, it involves a compilation step where source code is converted into bytecode (.pyc). This bytecode is then executed by the Python Virtual Machine (PVM).
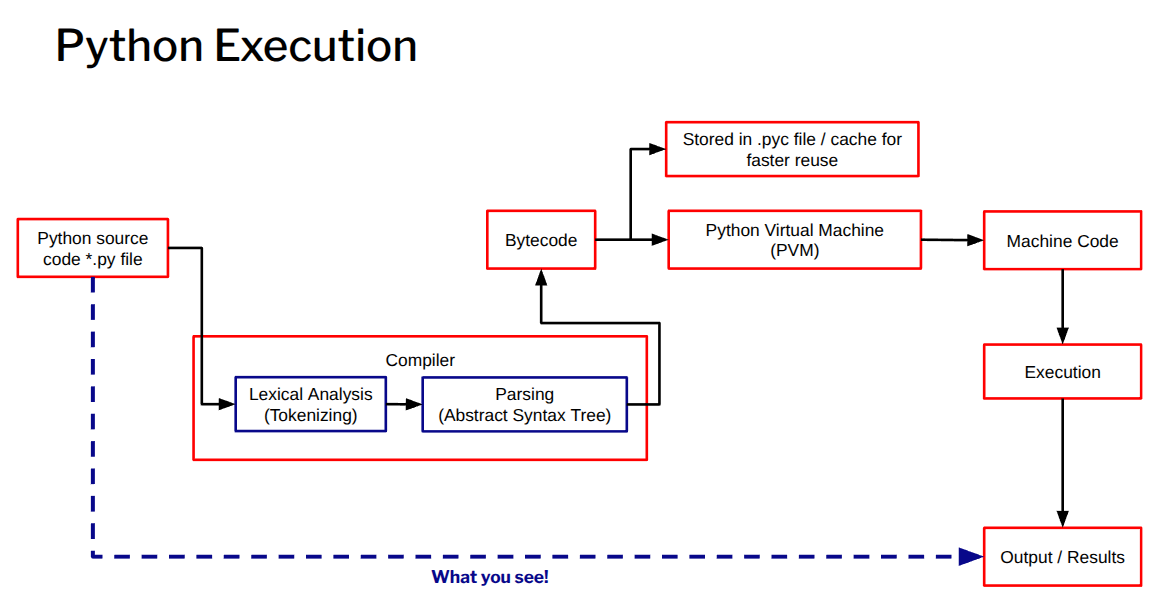
Detailed Execution Steps:
Source Code: Python code is a file with a
.pyextension.
Compilation to Bytecode: When the program is run, the Python Compiler first translates the source code into an intermediate format called bytecode. During this phase, it also checks for syntax errors. This bytecode is a set of instructions tailored for the Python Virtual Machine. This bytecode is a platform-independent representation that is not specific to any operating system or hardware. The compiled bytecode is then stored in a .pyc file. For faster loading in future runs, the bytecode is saved as a
.pycfile in a__pycache__directory. If a script is run directly, e.g. pythonmyscript.py, Python compiles it to bytecode in memory only. After execution no bytecode is saved. So.pycfiles are only created when a file is imported and when chasing is enabled (which is by default).
Execution by the Python Virtual Machine (PVM): The bytecode is then passed to the Python Virtual Machine (PVM), which acts as an interpreter. The PVM reads the bytecode instructions and translates them into machine-specific (binary) code that the computer’s CPU can understand and execute.
Execution and Output: The computer’s CPU executes the machine code instructions, interacts with the hardware (memory, I/O devices, etc.), and produces the final results or output of the program.
This flow ensures that Python is platform-independent at the bytecode level, as any system with a compatible PVM can run the same bytecode.
CPython is the reference implementation written in C. CPython functions as both a compiler and an interpreter. It first compiles Python source code into an intermediate format called bytecode, which is then executed by the Python Virtual Machine (PVM), a runtime environment written in C.
Python Code goes through parsing, complication and execution. Bytecode is the intermediate representation.
CPython is a stack based virtual machine. This means that it executes instructions using a Last-In, First-Out (LIFO) stack data structure to store and retrieve data, rather than using general-purpose registers.
Inside the CPython VM, each function call has an associated “frame,” which contains a specific “evaluation stack” (or “value stack”). This is where most of the work happens.
The Python Virtual Machine (PVM), which is part of the CPython interpreter, is written in the C programming language and uses the standard C API and C runtime library to make calls to the operating system. So instead of talking to the OS directly from Python code (which would not be platform-independent), the PVM includes an implementation layer (written in C) that uses the underlying OS’s own Application Programming Interface (API) to perform tasks using the Operating System.
So Python’s execution model combines interpretation with compilation. The Bytecode is an intermediate representation between the high-level Python source code and machine code. Bytecode is the intermediate representation that the PVM executes. The bytecode is more efficient to run compared to interpreting the source code directly.
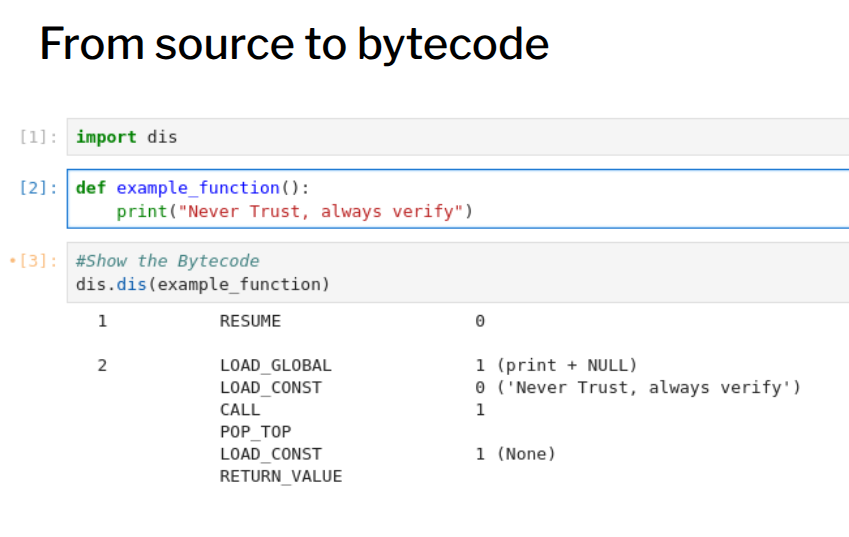
Below is an example how you can see how Python code is compiled to bytecode:
Memory Abstraction in Python: Security Benefits and Trade-offs¶
Unlike lower-level languages such as C or C++, Python does not allow developers to directly manipulate memory addresses. There are no pointers that can be arbitrarily dereferenced, and memory allocation and deallocation are handled automatically by the runtime. This abstraction significantly reduces the risk of certain low-level vulnerabilities, like Buffer Overflows.
In languages like C, developers must manually manage memory buffers. A common vulnerability is a buffer overflow, where data written beyond the bounds of an allocated buffer overwrites adjacent memory. This can lead to crashes or, in severe cases, arbitrary code execution.
C example (vulnerable):
char buffer[10];
strcpy(buffer, user_input); // No bounds checkingIf user_input exceeds 10 bytes, the program may overwrite memory and be exploited.
Python equivalent (safe by design):
buffer = user_inputPython strings automatically resize, and bounds checking is enforced internally. As a result, classic buffer overflow attacks are not possible in normal Python code.
Security Trade-offs: New Classes of Risks¶
While Python’s memory abstraction improves safety, it also introduces different security concerns.
Denial of Service via Resource Exhaustion Because Python automatically allocates memory, a program may unintentionally consume excessive resources if user input is not properly constrained. Example:
data = "A" * user_provided_sizeIf user_provided_size is extremely large, this can cause high memory usage and potentially crash the application or system.
Unsafe Use of Dynamic Features
Python allows runtime execution of code and dynamic access to objects, which can be dangerous if misused. Example:
eval(user_input)Although this does not corrupt memory, it can allow an attacker to execute arbitrary code within the application’s context.
Reliance on Native Extensions
While Python itself is memory-safe, many performance-critical libraries (e.g. NumPy, cryptographic libraries) are written in C. Vulnerabilities in these native extensions can reintroduce classic memory issues such as buffer overflows.
Example:
A Python application calls a vulnerable C extension.
An attacker triggers a flaw in the extension via crafted input.
Memory corruption occurs outside Python’s safety guarantees.
Summary
Python’s abstraction of memory management removes an entire class of low-level memory vulnerabilities, making applications safer by default. However, this does not eliminate security risks. Instead, it shifts them towards higher-level issues such as resource exhaustion, unsafe dynamic behaviour, and vulnerabilities in underlying native code. Effective security testing must therefore focus not only on memory safety, but also on how Python features are used within the application.